Distributed computing networks
Introduction
The computing industry began its growth in middle of 20th century and slowly started to become sort-of the new hype. Since then, computers started to be more and more involved in different activities, which over time required more and more computing power. Unfortunately, even today’s advanced computers (even quantum computers) are not yet powerful enough to handle, for example, difficult and precise calculations for scientific research works. Distributed computing network offer high performance power to prices ratio and thus are great for heavy workloads.
The definition
When your PC turns out to be extremely slow to solve a task, there are basically 2 fundamental things you can do. First, you can go ahead and buy a new, more powerful computer to do the job. This concept is known as vertical scaling. Second, you can buy a new PC with the same specs, place it near the old one and force them both to solve different parts of the task in parallel. This is known as horizontal scaling. Depending on the task type, requirements, software available and working environment, you decide whether to make use of vertical or horizontal scaling. At this point, you might realize, that distributed computing networks are "kinda" a derivative of horizontal scaling. In this article, we will go through the different types of distributed computing networks and how they are used in the real world.
When distributed computing is preferred over "standard" computing
Nowadays, more and more software is being written and optimized to work in a distributed network. Sometimes, you might prefer distributed network in order to gain better performance to expenses ratio. Sometimes, the usage of distributed network is your task requirement by design. For example, web scraping isn’t the thing you can always do with a single computer or, worse, with single IP address. Your computer will immediately receive a tone of captcha responses and you will end up with nothing, whereas distributed network might offer you thousands of computers with thousands of different IP addresses.
Centralized and decentralized computer networks
All distributed computing networks can be divided into 2 groups: centralized and decentralized. The difference is obvious. Centralized systems consist of one (or more) so-called command-and-control server, and, hence are often called server-based. Decentralized systems do not have any command-and-control servers. In order for decentralized networks to function normally, a synchronization mechanism might be required. For most of them, this mechanism is a blockchain, hence they are sometimes referred to as blockchain-based. The perfect example of decentralized computing system is any cryptocurrency like Monero, Bitcoin, Etherium.
Botnets
There is also one system, which I myself can’t call centralized and decentralized. This system is known to be called a botnet. Botnets are usually created, managed and controlled by malicious actors in order to provide other malicious actors with DDOS, malware spread and other services on the dark web. Depending on the size of the botnet and from what computers it consists of, we can actually correlate it with one of the well known computing network types (centralized or decentralized). For example, if hackers end up taking over some company’s network with a bunch of public ip addresses, they can use them to source commands to other computers in a botnet. Otherwise, without public ip addresses, hackers have to risk and host their own command-and-control servers, obviously making the system centralized.
"Legal" botnets
Obviously, not all botnets should be considered illegal (sort of). There are organizations (which, for sure, were involved in illegal activities, I bet) which specialize in botnet management for some legal purposes, for example, web scraping, scientific computations, etc. One everybody knows quite well is called "Massive". The hilarious thing is that on their website they literally have a FAQ question "What differs Massive from a botnet?" with a huge wall of text explaining the non-existing difference.
Introduction to anonymous communication networks
Besides "mostly" being used for computation purposes, distributed computer networks can also handle other kinds of tasks, for example, anonymous traffic routing. One example, which literally everybody knows is Tor, which we will discuss in depth, and I2P, which is quite similar to Tor (obviously, there are more alternatives, but we will discuss only 2 mentioned).
Tor in-depth
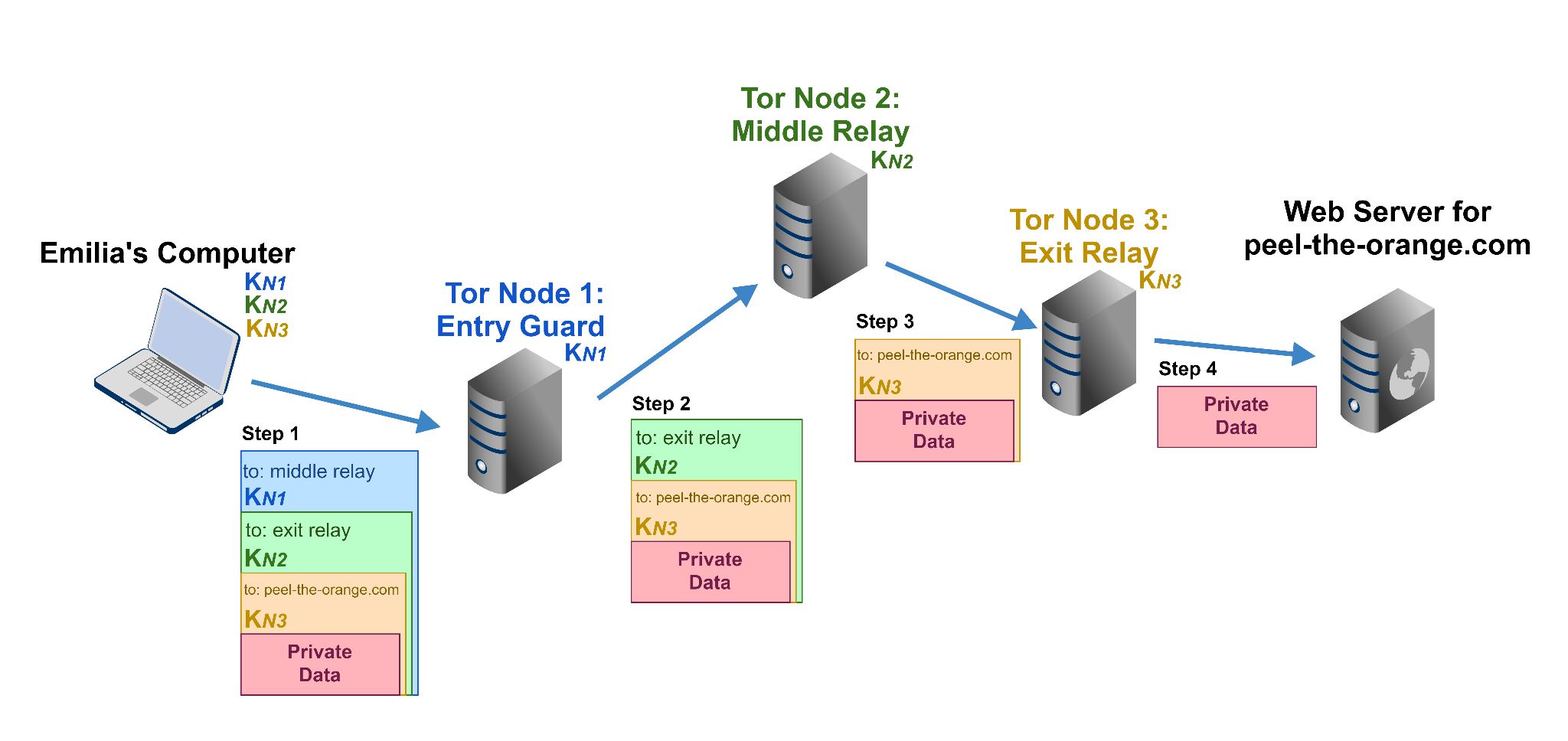
Tor, or Tor project, or Tor protocol, or the Onion routing project is what powers the dark web, or deep web, developed in the early 1990s by 2 American researchers to establish secure and anonymous communications between different departments of US NAVY throughout the world. The project became public in the early 2000s. The reason why it became public and open-source is quite obvious: were American intelligence members to use this network alone on their own, they would have been immediately detected. Websites on Tor and called "onions". That’s because the only TLD (top level domain) available here is "onion.". Second level domain names are also quite different from what you are used to see in the clear web: it can start with some human-readable word (which, on my experience hasn’t been more than 8 characters in size) but then it has some alphanumeric mess and everything sums up to the name of length 64. This information is kinda useless, because you better see and experience everything yourself. The real interesting thing about Tor is how anonymity preserving traffic routing happens. The network consists of 3 types of nodes (or, computers): entry guards, middle relays and exit nodes. When connected to the Tor networking, your computers also becomes a router for other people traffic. Entry guards are the nodes which you initially send the traffic to. These nodes can expose your IP address and hence, the "approximate" location. When you send a packet to the entry guard, it first gets encrypted a bunch of times by your computer and then gets sent. Data packets travel from entry guard to middle relay to exit node, each trip discards one layer of encryption. This is where the "onion" association comes from.
How I2P is different from Tor
I have also mentioned I2P as a protocol, similar to Tor. It also provides end users with anonymous communication abilities, but it is much more difficult to setup and once done, might take days to get online, which does not make it some kind of "go-to" solutions in comparison to Tor. On the other hand, I2P implementation is much more secure, the network itself has less users than Tor, hence it is less being spied by governments and more used by illegal actors.
Conclusion
Nowadays, when quantum computers are still not yet ready for real-world tasks, distributed computing is gaining more and more popularity (obviously, I am not talking about anonymous traffic routing systems here, the term "distributed computer" there is irreplaceable). The biggest advantage here is that it might be significantly cheaper (and sometimes faster, depending on the task) to mobilize more computers throughout the world, instead of running heavy workload on a single computer.